5. 整数的二进制存储
使用二进制存储整数是再自然不过的事,但这里面也确实有一些小问题需要解决:
- 应该用固定的二进制位数存储整数,还是用不固定的二进制位数存储整数?
- 如何来存储负数呢?
面对这些问题,大部分计算机语言几乎都不(相)约(互)而(抄)同(袭)地选择了相同的方式来处理
固定位数的二进制存储
几乎所有的计算机语言都选择了使用固定的二进制位数来存储整数
什么叫固定的二进制位数呢?比如说,我选择8位的二进制来存储整数,这就意味着,你哪怕存一个十进制数字2,我也会使用8位的二进制来存储0000 0010,看到了吗,在不足8位的时候,使用了0来进行填充。
这样做的好处是显而易见的,当使用了固定的二进制位数来存储后,程序在运行时,只要遇到读取数字,就可以直接告诉CPU,请你读取8位,就能读到一个完整的数字,这就避免了搞不清楚数字在哪里结束的问题。这种设计方式非常有利于程序的运行。
如果要更加深入的理解编程语言是如何确定这个某个区域是不是数字,以及如何告诉CPU读取多少位,就要去研究「汇编语言」和「编译原理」了。
对于初学者,简单的理解本文的内容即可。
然而,这种机制同时带来了一些明显的副作用,这些副作用主要体现在下面两个点:
- 存储较小的数字时会导致内存空间的浪费(存储
2时在前面填充了很多个0) - 存储较大的数字时会导致内存空间无法容纳(8位的二进制最多可以存储
个数字)
为了寻找一种折衷的解决办法,一些计算机语言提供了不同的整数类型供开发者选择,比如Java,它提供了4种整数类型:
| Java的整数类型 | 占位 | 可存储的数字数量 |
|---|---|---|
| byte 字节型 | 8 | |
| short 短整型 | 16 | |
| int 整型 | 32 | |
| long 长整型 | 64 |
这样一来,开发者就要根据实际的情况选择一个合适的整数类型来存储整数了。
比如,存储一个年龄,每个年龄用字节型byte就完全够了,而要存储天文学中的各种数字,就需要使用长整型。
从另一方面,也说明了在计算机语言中,可存储的数字区域是有限的,计算机无法存储极其大的数字
如果要存储极其大的数字,可以考虑使用后续章节介绍的浮点数来存储,它通过牺牲数字的精度来完成对大数字的存储,同时,它也可以存储小数
而你仔细观察会发现,无论是什么整数类型,它的占位始终是8的倍数,也就是字节的倍数,这是因为计算机的存储特点,决定了要么占满一个字节,要么不占,不能出现占一半的情况,具体的原因参阅「3. 从二进制到十六进制」
如何存储负数
现在,第一个问题解决了:使用多种固定长度的二进制位来存储整数
第二个问题浮出了水面:负数怎么办?
聪明的工程师很快想到了一种方案:把二进制的第1位作为一个特殊的位,它如果是0,则表示这个数字是正数,如果是1,则表示这个数字是负数,他们把这个特殊的二进制位叫做符号位。
很明显,符号位决定了这个数的正负符号。
一个8位的整数,可以表示
比如,-2这个数字,如果用8位的二进制表示,可以表示为:1000 0010,我们把这种仅改变符号,数字表示方式不变的二进制称之为原码。
原码非常容易被人理解,但是对于CPU的运算是一个巨大考验,为什么呢?
这是因为CPU的电路设计,对加法的处理是非常简单快速的,而对于减法却非常困难。
这就需要找到一种方案,把对减法的处理当作加法。
如果对原码不作任何处理,直接相加,比如-2 + 3就会出现下面的情况:

这个结果是明显不对的,那该怎么办呢?
工程师总是很聪明的,他们发现这些问题发生的根本原因,就是因为负数的出现,如果我把负数单独处理一下不就行了么。
于是,负数在存储时,不是直接存储的原码,原码是给人看的,真正存储的时候,会存储反码。
所谓反码,是把负数除符号位以外的数字全部取反,即0变1,1变0。
于是-2变成了1111 1101。
好,我们现在再来算一次

怎么样?还是不对对吧,是不是少了一个1?别着急,马上就要搞定了,我们只需要在得到负数的反码后,再加1即可。
反码加1之后对结果,称之为补码
补码才是负数存储的真实形态
-2的反码1111 1110,再来算一次
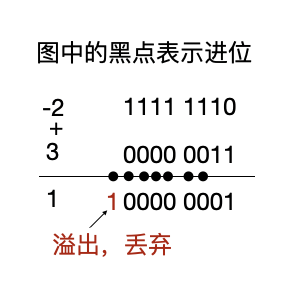
终于正确了!
大家可以自行多试一些数字,会发现都没有问题
于是,我们可以得出以下结论:
- 负数的在存储时,会先得到原码,再得到反码,然后得到补码,最终存储的是补码
- 如果要阅读一个负数的原始二进制(绝大部分情况下都不会有这样的需求,计算机语言会自动帮你完成转换),需要先去掉补码(减1),得到反码,然后再取反,得到原码,再转换成十进制。
- 8位最小负数的补码是
1000 0000,它和最大整数0111 1111(127)相加的结果刚好是1111 1111,推导出对应的原码是1000 0001,恰好等于-1,因此,1000 0000不是-0,而是最小负数-128。